by
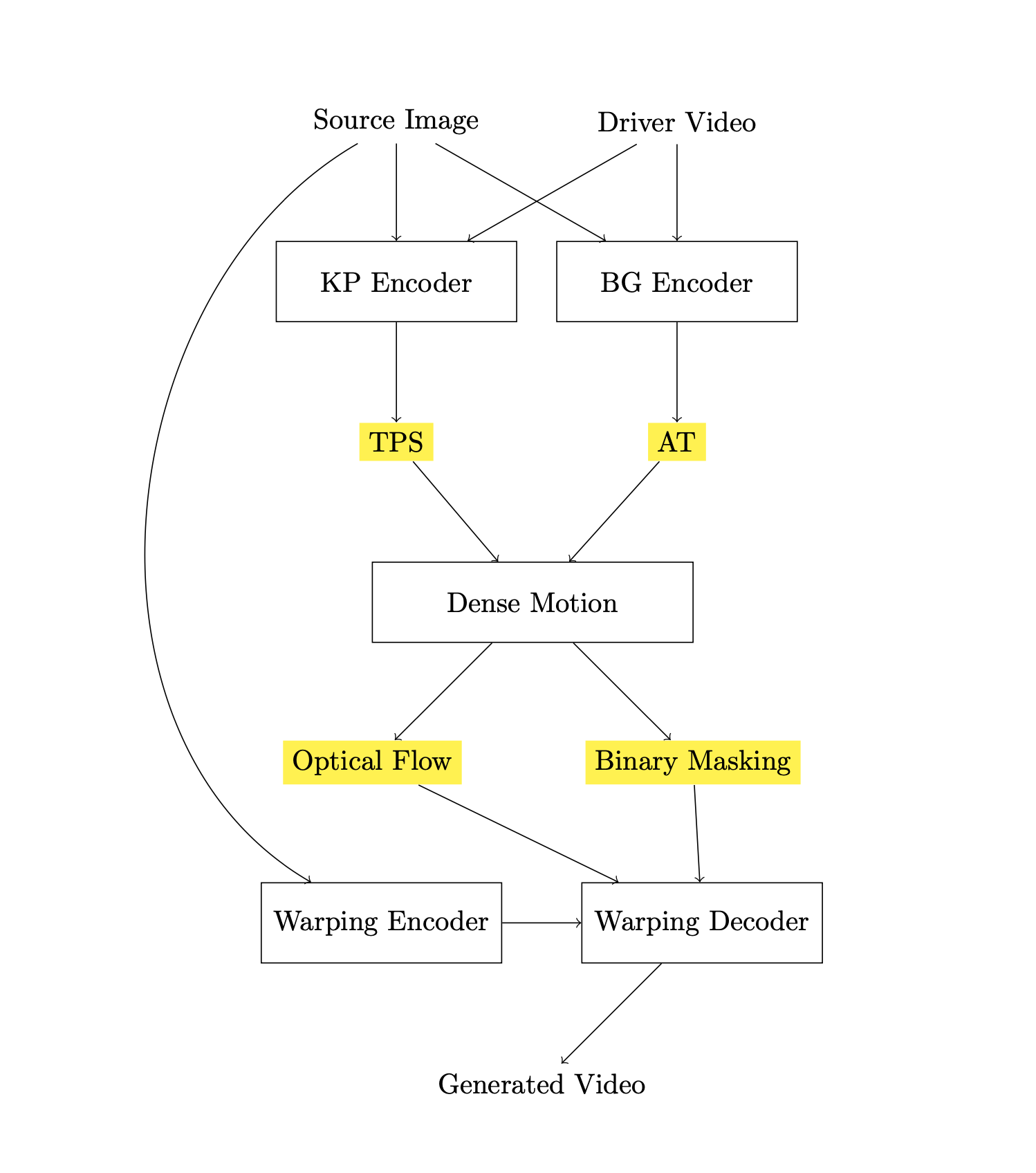
This work was focused on utilizing neural rendering techniques and taking inspiration from recent advancements in motion transfer methods to animate static objects driven by source motion. face2face was motivated by the recognition of the challenges faced by current unsupervised methods, particularly in scenarios where a substantial pose gap exists between source and target images. To address this challenge, we developed a pre-trained, unsupervised motion synthesis module. This approach involves a method to estimate hidden motion using flexible grids, making it easier to create detailed flow fields. This motion information facilitates the transformation of embeddings from the source image to align with the features of the target image. To improve the quality, we added adaptive layers at different levels, effectively addressing and filling the missing elements. This refinement significantly enhanced the generation of high-quality images and videos.
In this, the resulting adaptability is evident in its successful animation of a broader range of objects and pixels, including talking heads and upper body parts. Through experimentation, this method exhibited superior performance on benchmarks, exhibiting noticeable improvements of around 5-10% in animation metrics compared to existing state-of-the-art approaches.
What's the downside!Although face2face performs really well on the diverse features and has better adaptability, but certain times, it gets stuck. Additionally, the amount of time it takes to generate the video is a bit longer than expected. Also, this model generates some high-quality videos, but that is not up to the mark, and to make the resolution higher, we still need a resolution upscaling model.
@article{
face2face-bhumanai,
title={face2face: One-Shot Talking Head Video Generation from a Static Source Image},
author={Taneem Ullah Jan},
year={2023}
}