
AI Researcher and Engineer taneem@erisinnovate.ai |
Taneem Ullah Jan I am currently the AI Lead at ErisAI, where I lead research and engineering of production-grade AI systems spanning LLMs, multimodal models, retrieval, memory, and agentic workflows. I oversee model design, system architecture, and deployment for reliable real-world AI applications. Previously, I was an AI Researcher at VOLV AI and a Research AI Engineer at BHuman AI. |
Research WorkMy work spans multimodal learning, generative modeling, and agentic AI, with a focus on building reliable systems that move from research into real-world deployment. |

|
Ownify-AI: Engineering a Multi-Tenant Infrastructure for Applied
Intelligence
Taneem Ullah Jan Work done at ErisAI [project page] An engineering perspective on building production AI systems through multi-tenant infrastructure, knowledge isolation, and system-centric AI. |
|
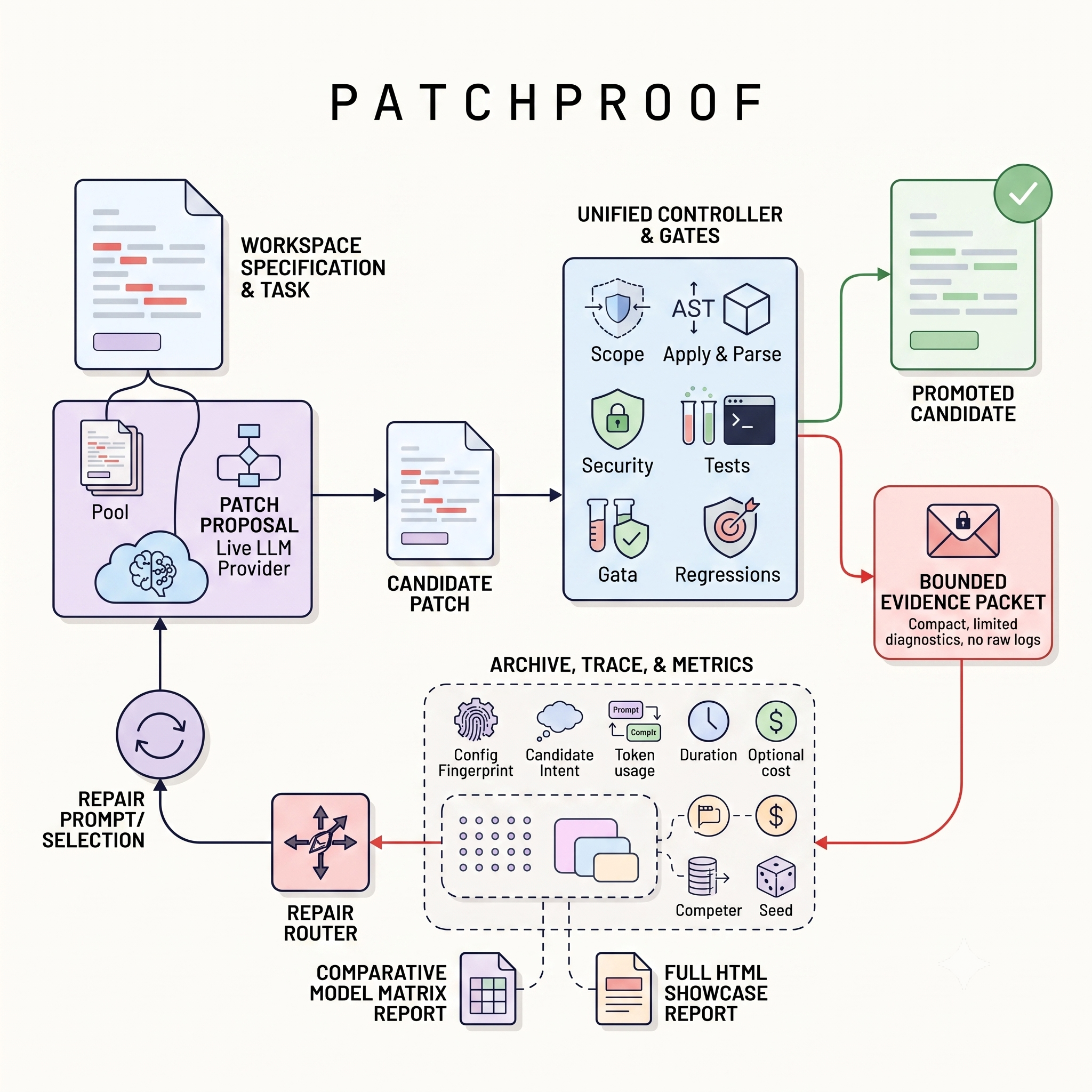
PatchProof: Gate-Verified Repair Search and Reproducible Benchmarks for
Coding Agents
Taneem Ullah Jan [project page] A gate-verified repair search framework for coding agents that ensures reproducibility, verifiability, and auditable lineage of code patches. |
|
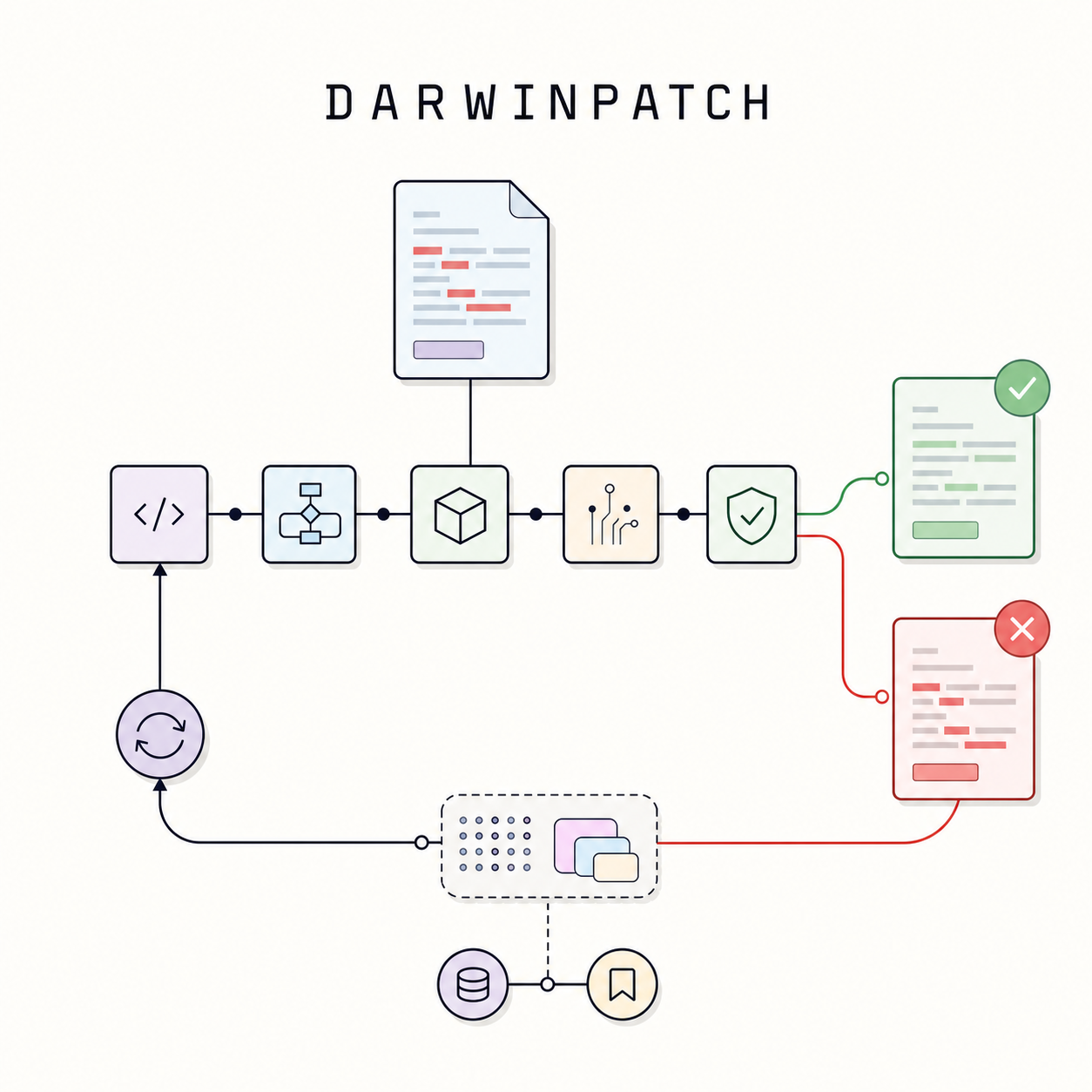
DarwinPatch: A Budgeted Repair-Search Controller for Reliable Coding Agents
Taneem Ullah Jan [project page] DarwinPatch is a budgeted repair-search controller for coding agents that converts failed patch attempts into bounded evidence, routes follow-up repairs through hard verification gates, and records auditable candidate lineage. |

|
Synapse: Designing a Research-Driven AI System Beyond the Base Model
Taneem Ullah Jan Work done at ErisAI [project page] A research-first look at how Synapse combines retrieval, routing, memory, verification, and runtime controls into a dependable applied intelligence system. |
|
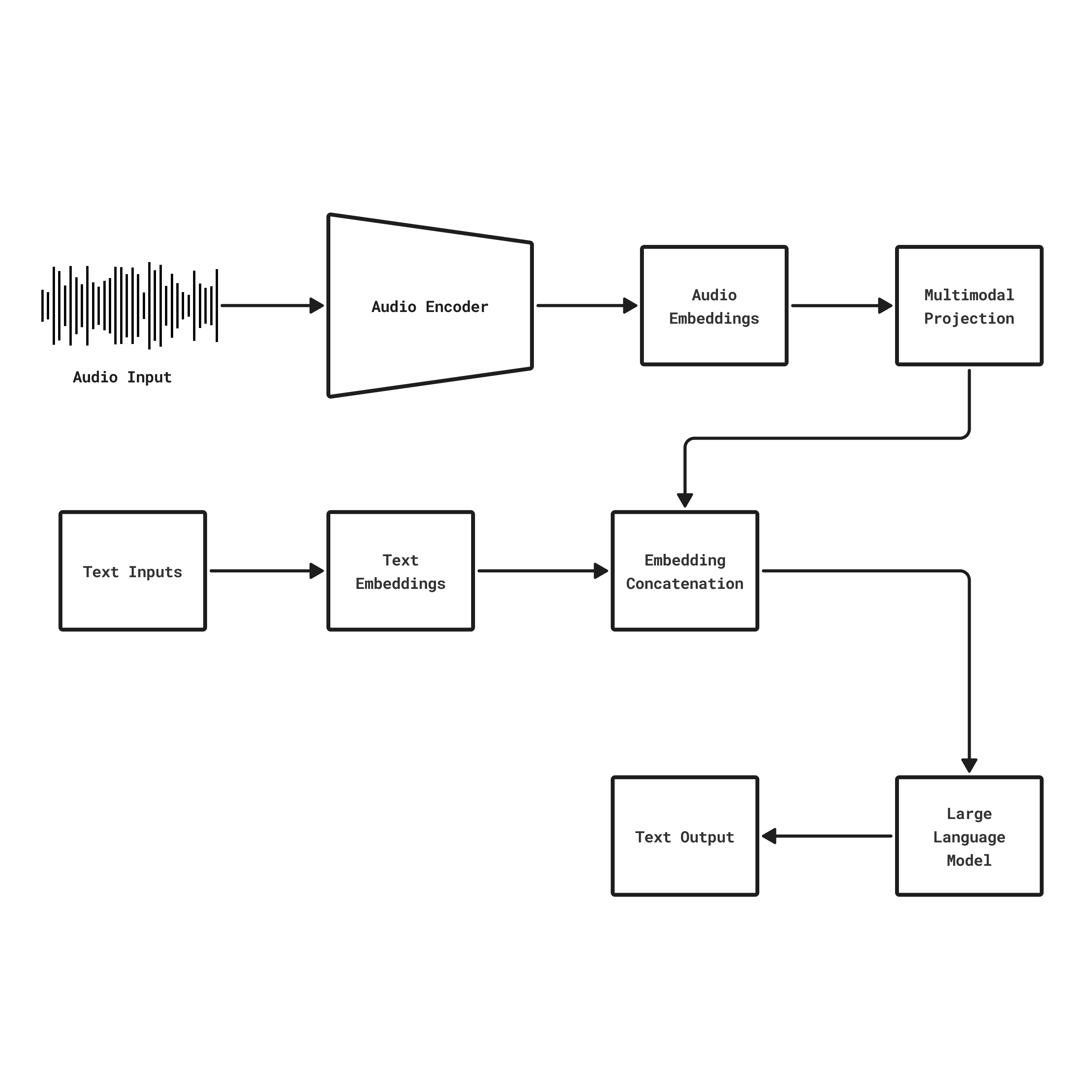
EmbedVoiceLLM: Efficient Multimodal Block-optimized Embedding-Driven Voice
Operations with extensible learning
Taneem Ullah Jan [project page] tldr: An embedding-driven approach combines audio encoders with multimodal projectors to enable direct speech-to-text processing, achieving significant performance while training minimal parameters through block optimization. |


|
FlexiSMPL: Flexible SMPL Body Modeling with Real-time 3D Visualization and
Measurement Control
Taneem Ullah Jan [project page] tldr: An interactive 3D body modeling system that allows real-time manipulation of human body shapes through intuitive measurement sliders with immediate visual feedback in a fully navigable 3D environment. |
|
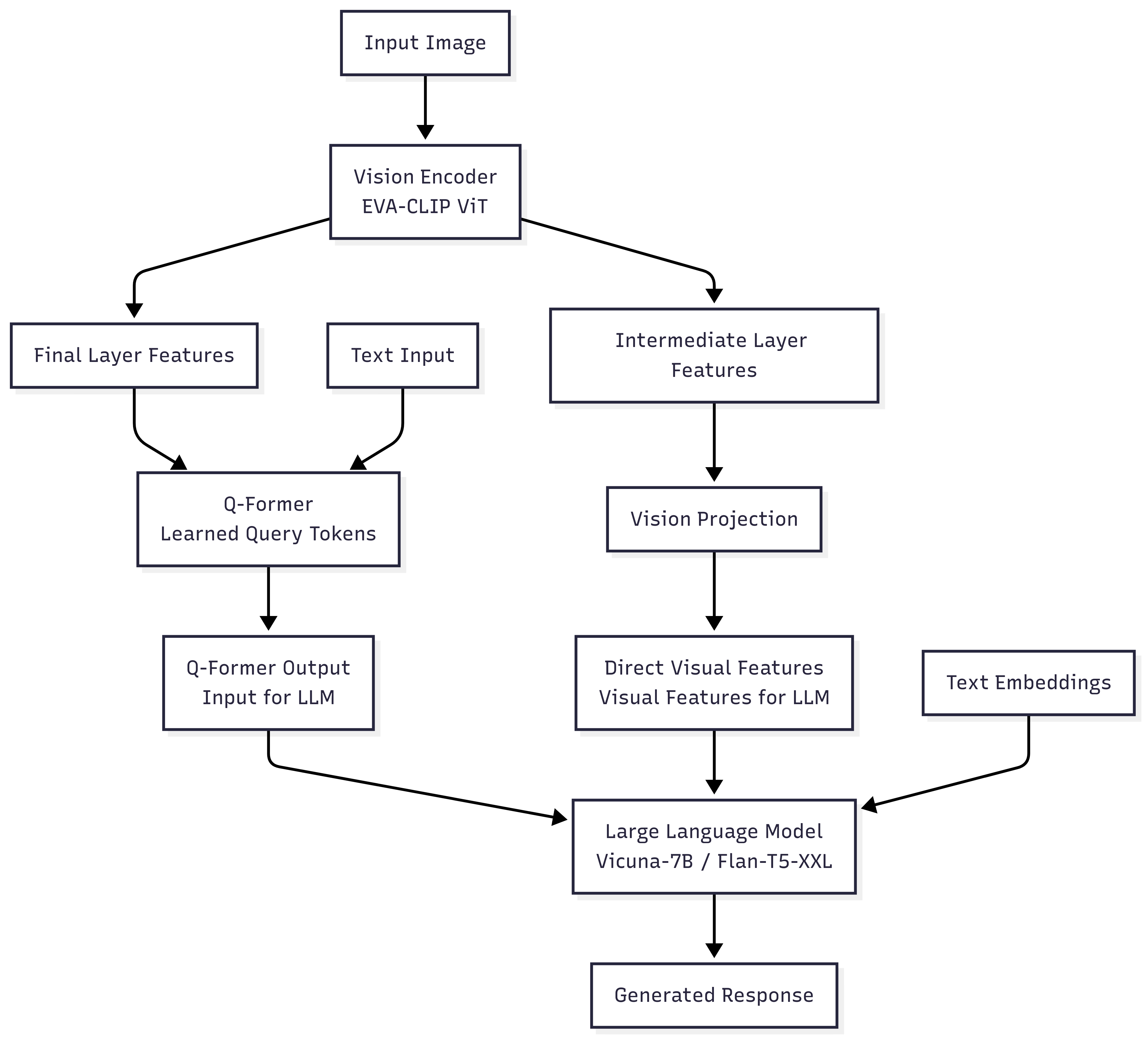
VMVLM: Vision-Modulated Vision-Language Models for Improved Instruction
Following
Taneem Ullah Jan [project page] tldr: VMVLM enhances vision-language models by using dual visual pathways, combining Q-Former queries with direct ViT feature injection for improved multimodal instruction following. |
|
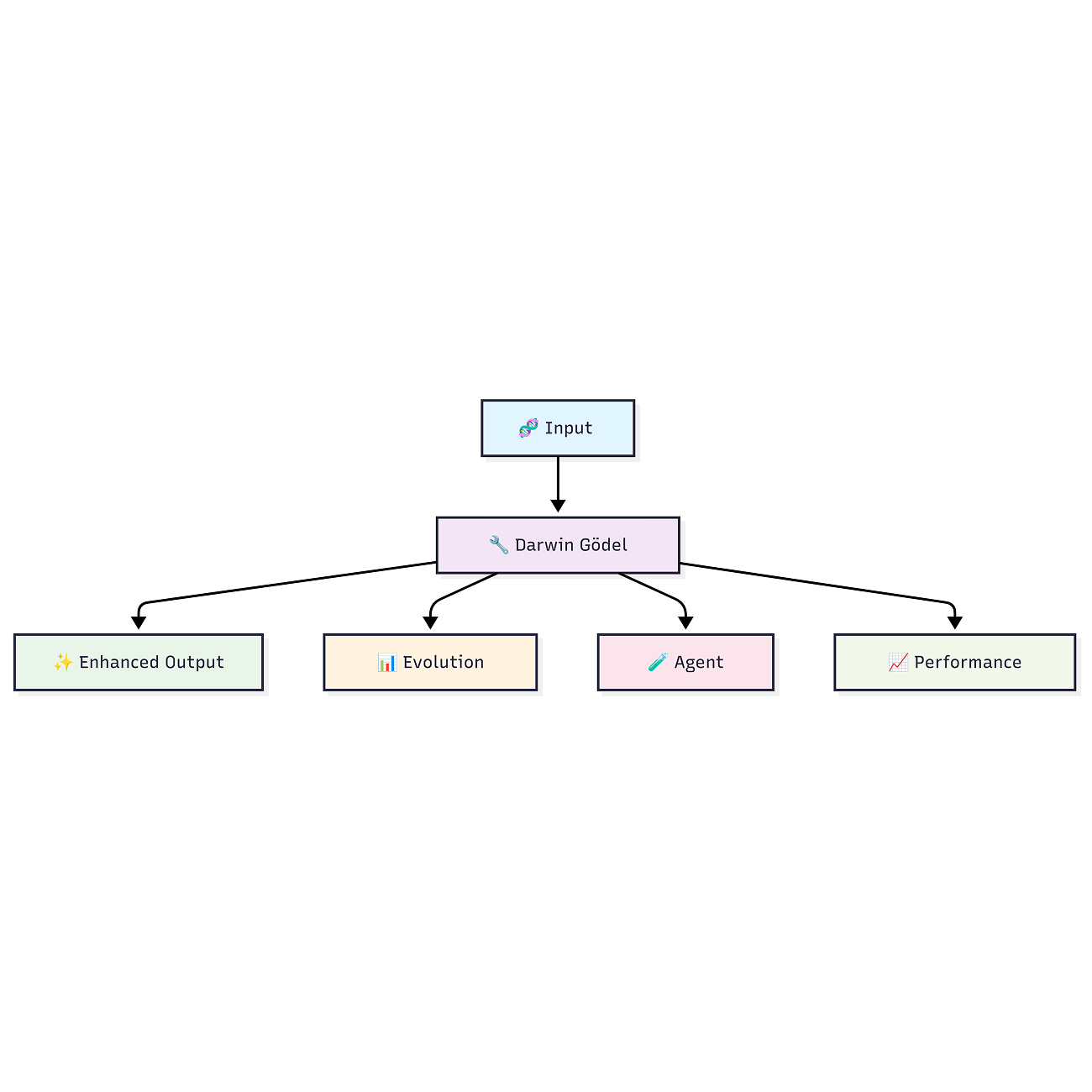
DGM-LLM: Darwin Gödel Machine
with Large Language Model Integration for Autonomous Code Self-Improvement
Taneem Ullah Jan [project page] tldr: A self-improving AI system that uses LLMs and evolutionary algorithms to autonomously enhance code across multiple quality dimensions. |


|
OmniFit-3D: A Unified Framework for 3D Virtual Try-On with Pose-Adaptive
Realism
Taneem Ullah Jan [project page] tldr: A unified framework for 3D virtual try-on that transforms simple 2D images into realistic 3D representations, by efficiently integrating clothing with the human body in a pose-adaptive manner. |
|
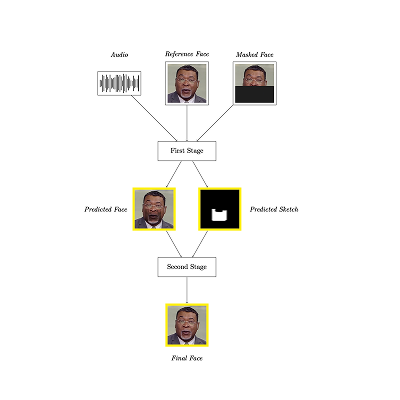
LipSyncFace: High-Fidelity Audio-Driven and Lip-Synchronized Talking Face
Generation
Taneem Ullah Jan [project page] tldr: A two-stage unified audio-driven talking face generation framework, which can render high-fidelity, lip-synchronized videos with improved inference speed. |

|
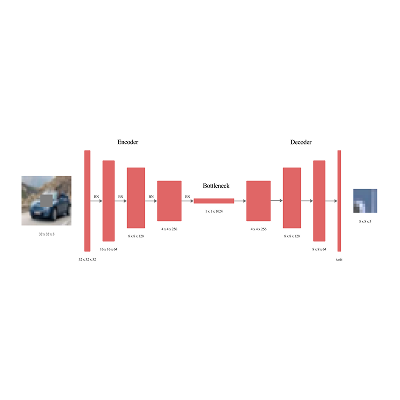
Beyond CNNs: Encoded Context for Image Inpainting with LSTMs and Pixel
CNNs
Taneem Ullah Jan, Ayesha Noor International Conference on Innovations in Computing Technologies and Information Sciences (ICTIS) and IJIST Special Issue, 2024 Track: Artificial Intelligence, Pattern Recognition & Image Processing [project page] [pdf] tldr: Current image inpainting techniques are too heavy; this paper introduces a Row-wise Flat Pixel LSTM, a small hybrid model for the efficient and high-quality restoration of small images. |
|
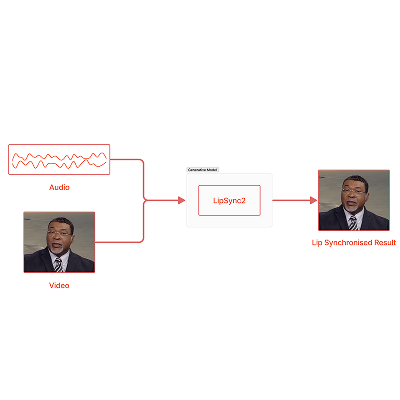
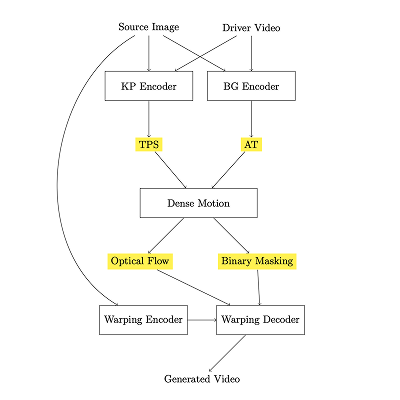
lipsync2: Talking Face Generation with Most Accurate Lip
Synchronization
Taneem Ullah Jan Work done at and for BHuman AI, 2023 [project page] tldr: A robust and efficient talking face generation model with highly accurate lip synchronization and full facial expressiveness with more extended audio and high-quality video resolutions. |

|
face2face: One–Shot Talking Head Video Generation from a Static Source
Image
Taneem Ullah Jan Work done at and for BHuman AI, 2023 [project page] tldr: An unsupervised one-shot talking head video generation model using neural rendering and motion transfer techniques with non-linear transformation to animate static images. |


|
face–swapping: Swapping Faces on Target from given Sources
Taneem Ullah Jan Work done at and for BHuman AI, 2023 [project page] tldr: Innovative face-swapping model that preserves the source identity features accurately while seamlessly adapting target attributes applicable to images and videos. |
|
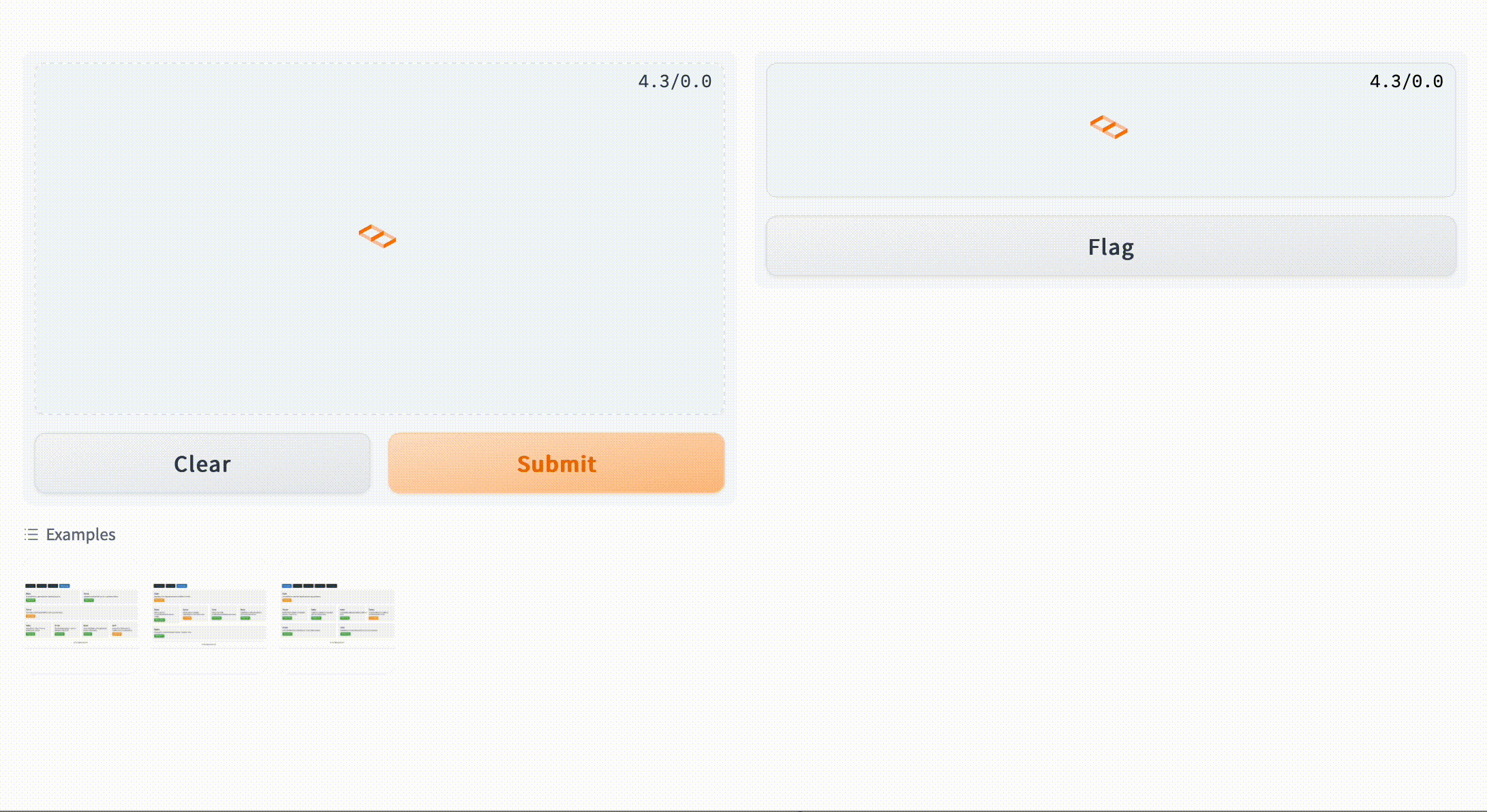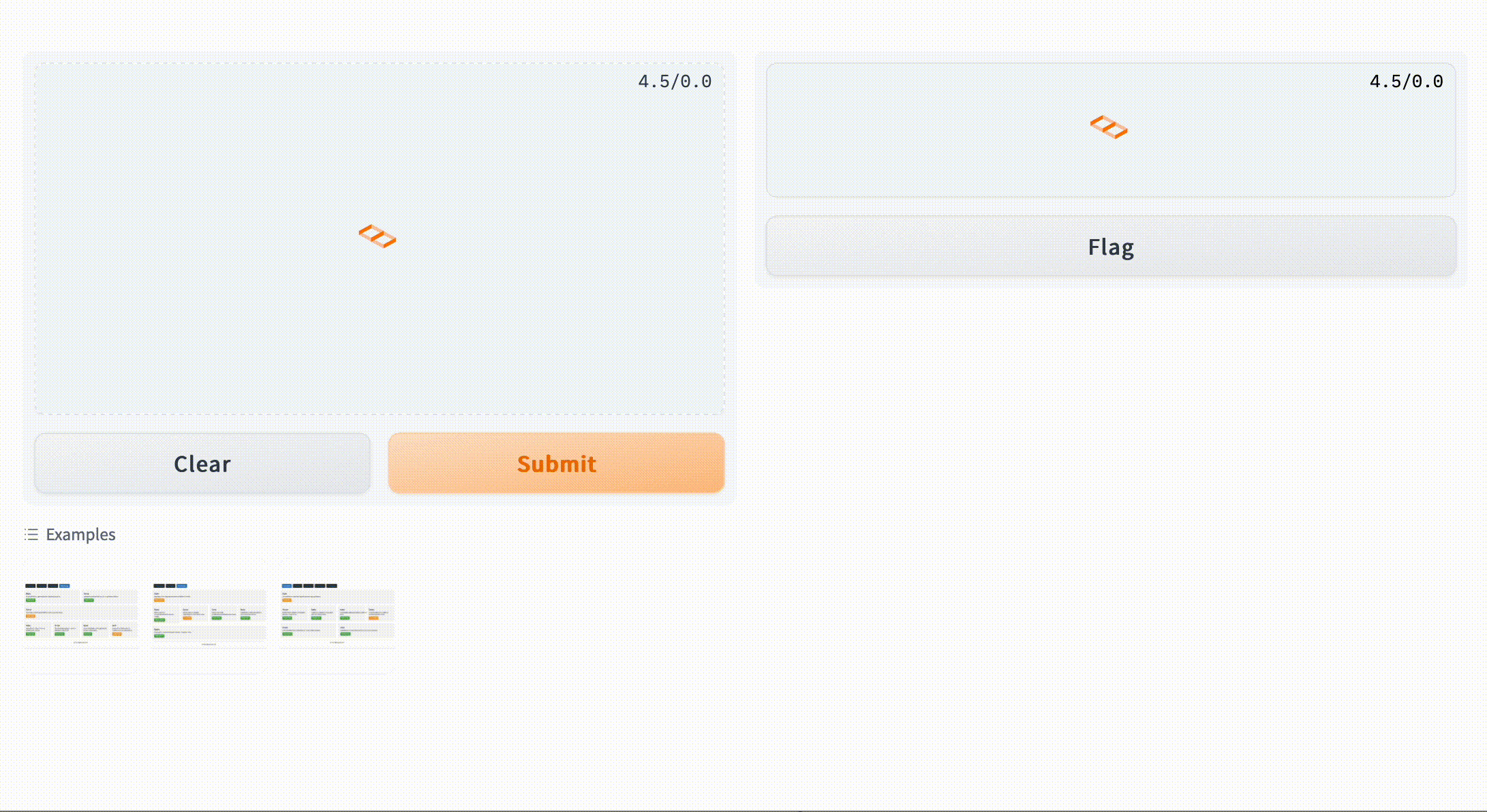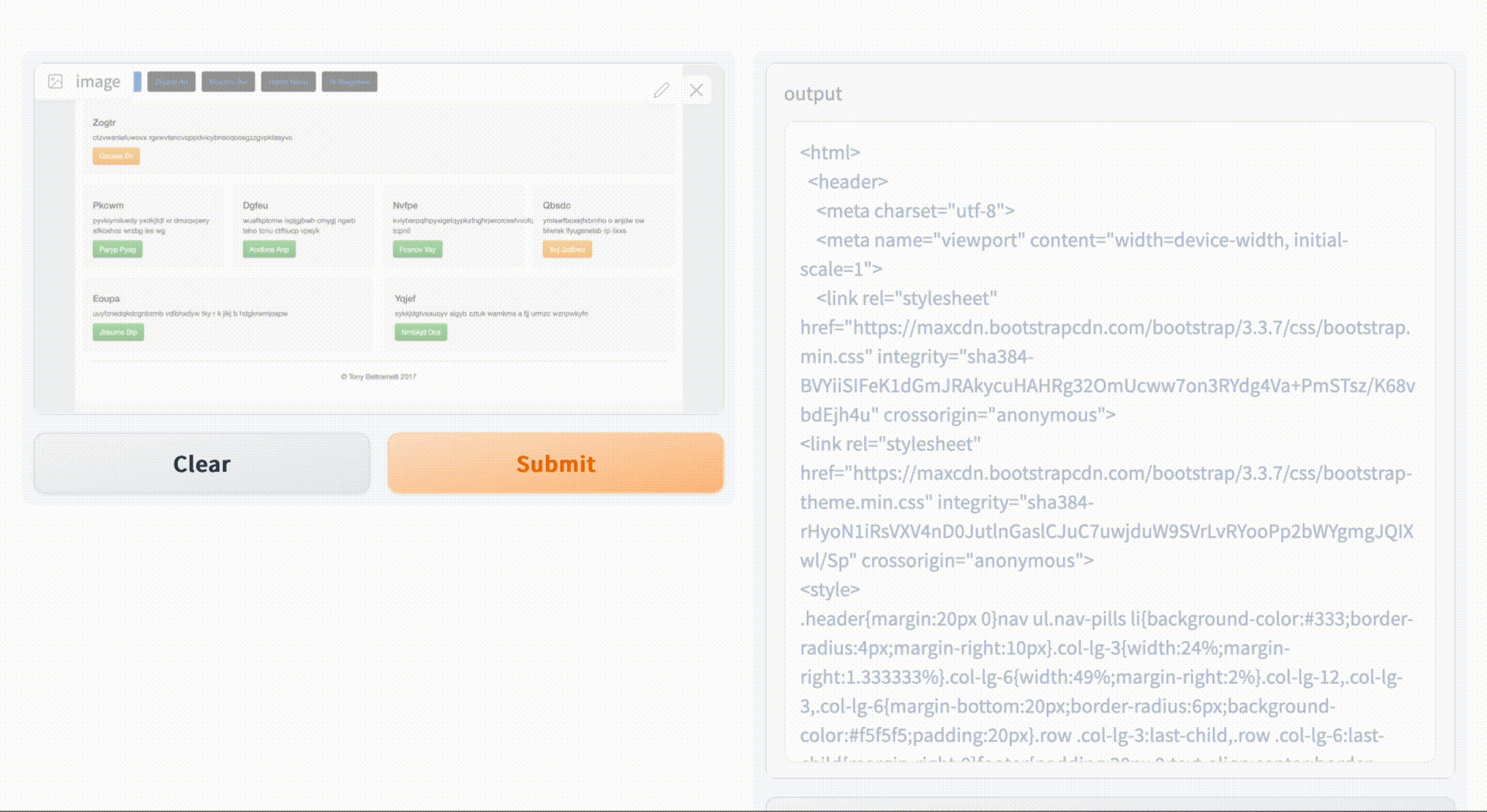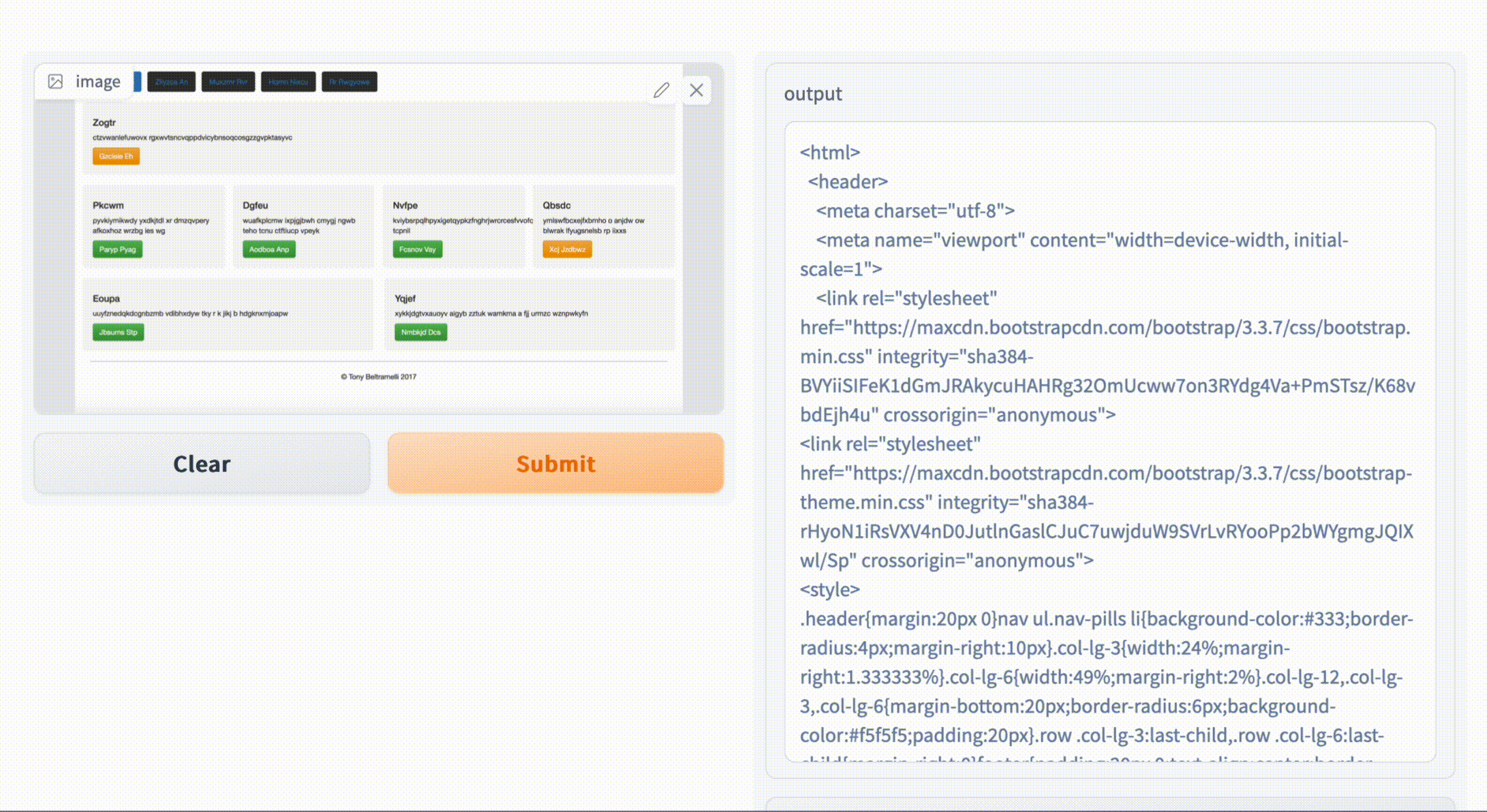
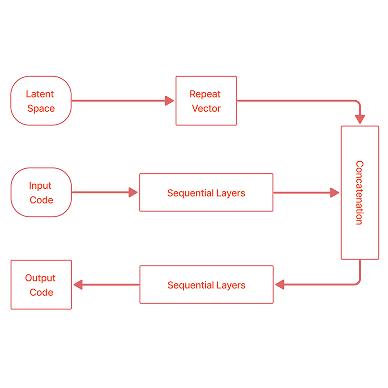
HTML Code Generation from Images with Deep Neural Networks
Taneem Ullah Jan, Zakira Inayat Journal of Engineering and Applied Sciences (JEAS), 2022 Track: Artificial Intelligence, Pattern Recognition & Image Processing [project page] [code] [demo] tldr: An accurate deep learning model converting GUI mockups into HTML code, streamlining web development for non-programmers. |
|
Thanks to Jon Barron for this template.
|